Solutions "Server side - Consentless - Cookieless" : à quoi joue la CNIL ?

Le monde de la tech semble se satisfaire de la disparition annoncée des cookies tiers. Notre position : le mieux est l'ennemi du bien. Celle de la CNIL interroge.
Publié le 24 avril 2023
A l'origine
Depuis quelques temps, Google a annoncé la mise en place de la "Privacy Sandbox" sur son navigateur Chrome, navigateur utilisé par environ 80 % des Internautes dans le monde. L'objectif annoncé pour ce nouvel outil consiste à supprimer à terme les cookies dits "tiers", c'est-à-dire des traceurs déposés sur les ordinateurs des usagers par d'autres sites que ceux visités, et qui permettent un suivi de navigation. Cette volonté de Google a pour but de tenter de s'aligner sur des navigateurs Internet concurrents, qui déjà proposent des options s'en approchant, quand d'autres encore sont en capacité de les supprimer purement et simplement. Si la Privacy Sandbox peine à être mise en place (des mois, voire deux ans de retard sur le programme annoncé), elle motive et contraint dans le même temps les entreprises de publicité programmatique à développer d'autres technologies de suivi. De façon générale, on se félicite de la disparition annoncée du cookie tiers et on en vante les bénéfices pour les usagers en termes de vie privée.
La réalité des faits mérite un peu plus d'attention.
Anecdote allégorique : un capitaine marin-pêcheur a répondu un jour à son matelot qui lui reprochait de naviguer trop près des côtes : "Je préfère être près d'un danger que je vois, que naviguer au large et heurter un danger que je ne vois pas". Idem pour le tracking. En effet, ne nous imaginons pas naïvement que la fin des cookies tiers signe l'arrêt du profilage comportemental à des fins publicitaires. Vous continuerez à voir des publicités ciblées, et pire : cela risque même de se faire sans votre consentement, en toute impunité. Des technologies alternatives existent depuis plusieurs années, mais peu (à vrai dire une seule) ne requiert peu ou pas de données personnelles. Parmi les technologies alternatives qui requièrent des données personnelles, on peut trouver la technologie dite server-side. Nous allons nous y attarder, en abordant deux points : sa description brève dans un premier temps, et surtout dans une seconde partie la position ambiguë de la CNIL sur le sujet. Le lecteur comprendra alors, s'il ne l'a déjà fait, l'anecdote maritime évoquée.
Qu'est-ce qu'une technologie server-side ?
Beaucoup de sites et d'articles décrivent cette technologie, ses avantages et ses inconvénients. L'objectif ici n'est pas de l'expliquer dans le détail, mais d'en décrire le principe dans ses grandes lignes, de façon la plus simple et schématique possible, ainsi que les différences qu'il présente en comparaison de la technologie qui utilise des cookies, dite "client-side".
Pour suivre et cibler le comportement d'un Internaute, la technique la plus répandue (encore aujourd'hui) est celle qui consiste à déposer des cookies dans l'ordinateur de l'usager et de les lire lorsque cela est nécessaire : cela s'appelle du tracking client-side.
Une autre technique consiste à mettre en place une étape intermédiaire entre les organismes publicitaires et d'audience d'une part, et le site visité d'autre part. Cet intermédiaire est matérialisé le plus souvent par un serveur. Pour simplifier, une seule entité collecte des données de l'utilisateur, puis les distribue à tous les organismes autorisés par le site. Ainsi, les partenaires publicitaires d'un site Internet ne déchiffrent pas d'information directement à partir de l'ordinateur de l'utilisateur, mais à partir du serveur intermédiaire.
Cette technologie, appelée "server-side", devrait potentiellement être nature à mieux faire respecter les droits de l'usager car l'éditeur d'un site peut décider, en définissant des "règles de comportement" du serveur intermédiaire, des informations qu'il transmet et de ses destinataires, et donc surtout de celles qu'il ne transmet pas. Elle apporte par ailleurs des avantages techniques significatifs pour les éditeurs en termes de performances et elle est, de ce point de vue, extrêmement intéressante. En revanche, elle nécessite des ressources non négligeables, tant en termes de développement que d'infrastructures. Mais, pour les défenseurs du respect de la vie privée sur Internet, elle présente, vous l'aurez compris, un immense inconvénient : elle est difficilement auditable. Le lecteur comprendra par le schéma ci-dessous que vu de la position de l'utilisateur concernant le tracking, cette technologie ne change strictement rien. En revanche, dans d'autres domaines (temps de chargement des pages entre autres), il y trouve un avantage certain. Le schéma ci-dessous, tiré du site "jentis.com", en résume le principe :
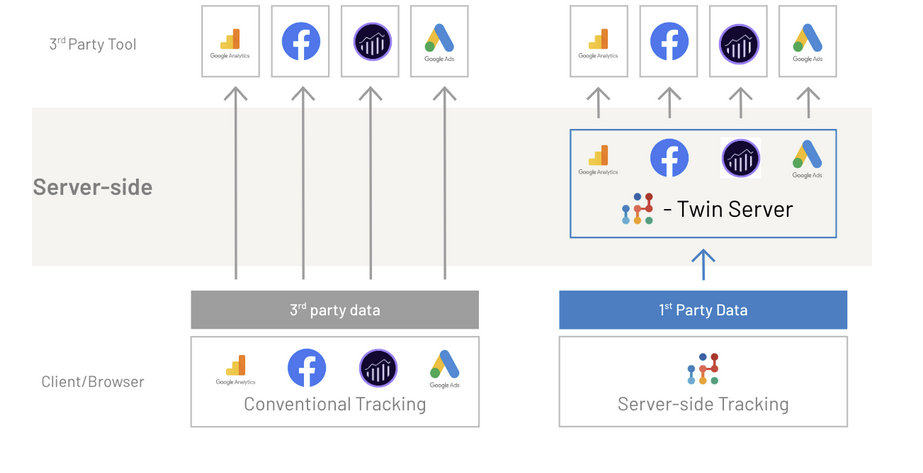
source de ce schéma (attention, site avec traceurs) sur le site de Jentis, ici
Techno server side = opacité du tracking.
On comprendra la différence fondamentale pour l'usager entre les deux technologies : un cookie, même tiers, se détecte sans difficulté sur un navigateur. Il peut être du reste supprimé ou bloqué par simple choix de l'usager (c'est là tout le sens et la raison d'être des fenêtres de consentement), ou encore par des programmes conçus pour cela (Adblockers notamment). Enfin, le législateur encadre de façon assez complète son utilisation : la réglementation existe, à défaut d'être appliquée. Lorsqu'une technologie server side est employée, il est beaucoup plus difficile de repérer les traceurs, qui du reste n'existent pas, ou du moins sont moins visibles et plus persistants.
Il est important de préciser à ce stade que la disparition des cookies tiers ne signifie pas la disparition de TOUS les cookies. Les cookies dits de "première partie", c'est-à-dire lus et déposes par l'éditeur du site, existent toujours. On a tendance à les présenter comme plus fiables, parce que mieux maîtrisés. Mieux maîtrisés, certes, plus fiables pour l'éditeur, cela est incontestable (puisqu'il évite l' "intrusion" de sites étrangers au sien), mais plus fiables pour l'usager, cela ne change en fait que peu de choses. Vous pouvez observer sur le schéma ci-dessus que l'on parle de "First party data", c'est-à-dire soit des cookies de première partie, soit des "données" de première partie. Quelles sont ces données ? Cela peut être par exemple une adresse IP, une adresse courriel "encodée" (on parle de "hachage" : opération qui consiste à transformer de manière irréversible une chaîne de caractères en une ligne composée de chiffres et lettres qui ne peuvent être décodés et dont cette "transformation" reste identique, l'opération correspondant à un standard très largement adopté. Retenez bien le terme, il vous sera utile par la suite), un pixel invisible, ou encore un ensemble de caractéristiques propres à votre ordinateur (on parle d'empreinte numérique ou de fingerprint en anglais). Ils ne peuvent être effacés par l'usager seul, et lorsqu'ils le sont, qu'on le veuille ou non, ils sont pour ainsi dire rapidement "reconstituables" dans la mesure où (par exemple), les caractéristiqes de votre ordinateur, à moins d'en changer, restent les mêmes. On pourrait les qualifier (même si le terme est très impropre) de "nouveaux cookies" : ineffaçables, inbloquables, quasi inaltérables et sans limitation de conservation de durée : de l'or pur pour l'Adtech.
Exemple concret et réel : vous ouvrez un compte gratuit sur un site de grande distribution, et fournissez votre adresse courriel. Cette adresse ne sera pas collectée telle quelle par des organismes aux fins publicitaires, mais en revanche sera hachée puis collectée : ceci constitue un magnifique identifiant qui persistera tant que vous n'aurez pas changé d'adresse courriel. Pinterest est championne en la matière et collecte, sur plusieurs grands sites français, votre adresse courriel hachée qui, sans pouvoir être déchiffrée, fait officce d'identifiant unique utilisateur, qui persistera et constituera un superbe traceur valant bien mieux qu'un bon vieux cookie de type "uuid" : identifiant universel unique ("Universally Unique Identifier"). Pourquoi ? Parce que, quel que soit l'appareil sur lequel vous naviguez, ce type de traceur reste le même, contrairement aux cookies qui sont différents selon l'appareil que vous utilisez et son navigateur.
Ainsi, sachant que le server side consiste à gérer des lignes de codes spécifique appelées balises (ou TAG en anglais : vous entendrez souvent parler de TAG Manager), on se permet de poser l'équation suivante, non du point de vue de l'éditeur, mais de celui de l'utilisateur :.

Non seulement cette technologie reste donc difficile à percer en termes de données personnelles collectées, mais encore pose-t-elle certaines difficultés d'ordre juridique. La position de la CNIL sur le sujet nous inquiète.
Parenthèse importante : il faut rappeler encore une fois que le server side n'a pas été à l'origine conçu pour profiler des utilisateurs, et apporte, on le répète, de nombreux et réels avantages pour les éditeurs mais aussi pour les usagers dans d'autres domaines. Il nous semble par ailleurs nécessaire d'émettre notre opinion selon laquelle il est heureux que des entreprises françaises développent et proposent cette technologie, dont, on peut s'en douter, le principal fournisseur est actuellement... Google, bien évidemment, avec Google Tag Manager en version server side. A titre d'exemple en France, Tag Commander, de Commanders Act se développe de manière significative sur le marché (tout en restant extrêmement loin du leader). Il est d'autre part important de comprendre que ce n'est pas la technologie en elle-même ni ceux qui la développent qui posent problème, mais les organismes Adtech qui l'exploitent.
Pourquoi évoquer ce sujet ?
Nous avons récemment publié une lettre ouverte à la CNIL qui exprimait notre inquiétude sur la bonne configuration de solutions d'audience suite à notre article sur le sujet. Dans cette lettre, nous avons évoqué un éditeur média auquel nous reprochions de déployer une ressource externe sans consentement. Le PDG de l'entreprise conceptrice de ladite ressource a répondu également par une lettre ouverte, dont un passage a fait réagir. Le voici :.

Qu'est-ce qui lui permet de tenir ce propos ? La référence juridique sur laquelle il se fonde est l'article 82 de la loi "informatique et libertés", article très important, si ce n'est fondamental car d'une certaine manière à l'origine de la création des fenêtres de consentement. Cet article est le suivant :

Les mots magiques encadrés en rouge : "accéder à des informations stockées dans le terminal (i.e. l'ordinateur ou le smartphone de l'utilisateur)" et "inscrire des informations dans cet équipement" (i.e. déposer des cookies ou des traceurs). Or, avec la technologie "server-side", même si celle-ci réalise en définitive la même chose que la technologie client-side, les organismes de ciblage n'ont pas forcément besoin d'aller piocher des données dans le terminal même de l'utilisateur, mais dans le serveur intermédiaire. Par ailleurs, la seule lecture d'une adresse IP peut ne pas se faire sur l'ordinateur en lui-même (le rédacteur de la lettre sus citée utilise cette agumentation). L'interprétation juridique est donc la suivante : pas de lecture ni d'écriture sur l'ordinateur de l'utilisateur, donc, pas besoin de consentement. Cette interprétation, vous l'imaginez bien, ne correspond bien évidemment pas à notre position, car la nécessité du consentement ne se limite pas au cas de figure décrit par l'article 82 de la loi Informatique et libertés sus-citée. De la même manière, des organismes de publicité en ligne exploitent cette vision en interprétant les règles de manière arrangeante. c'est également le cas de nombreux concepteurs de "Content Managment System" (CMS), qui sont entre autres les interfaces permettant de concevoir un site web sans codage, et utilisent le server side. Sur ces CMS se trouvent des options supplémentaires (add ons), contenant potentiellement des traceurs indétectables. Un PDG d'entreprise éditrice de fenêtre de consentement (CMP) déclarait sur Twitter l'été dernier à ce sujet, citation :
"Le nombre de trackers server-side configurés en toute impunité est vraiment inquiétant".
Cependant, et cela est heureux, il faut préciser à cet égard que le PDG de Commanders Act a réagi aux propos de la lettre ouverte évoquée plus haut, comme le montre ce tweet.

On partage bien évidemment cette position, mais pour autant, une argumentation juridique plus élaborée aurait été bienvenue, car si nous sommes totalement et fondamentalement d'accord sur l' "esprit du RGPD", nous n'avons aucun doute sur les positions technico-juridiques des défendants en la matière, et il faut hélàs s'habituer et chercher dans le détail la contre argumentation à l'éternelle position qui, trivialement, consiste pour les défenseurs de l'Adtech à faire observer qu' "il n'y a pas écrit "Jacques-a-dit" dans le RGPD". Bref, on pourrait considérer que c'est le jeu.
Mais ce qui nous heurte n'est pas tant le jeu joué par le monde de l'Adtech que la position de l'arbitre : la CNIL.
La CNIL : une position ambiguë
En octobre 2020, à l'occasion de l'édition des recommandations et lignes directrices de la CNIL, un groupement d'éditeurs a sollicité auprès d'elle une session questions / réponses. Observation plutôt positive que l'on peut faire d'emblée : la publication de ces recommandations a donc été prises au sérieux, et n'a été ni négligée, ni ignorée. En revanche, on peut raisonnablement voir dans la formulation des questions une malice certaine visant à mettre ces recommandations en contradiction avec elles-même. Morceau choisi ci-dessous, et sur ce point, il est heureux que la CNIL reste ferme.

Mais il existe deux autres questions dont on devine bien la réelle teneur au regard de ce que nous venons d'écrire, et dont les réponses, pour le moins, nous surprennent.
La première ci dessous, concerne ce que nous avons évoqué plus haut : ce que nous avons appelé les "nouveaux cookies". Maintenant que vous savez, vous comprendrez mieux l'intention visant à contourner la réglementation.

La seconde, beaucoup plus pernicieuse, ci-dessous :

Cette réponse de la CNIL, qui reflète à notre sens une interprétation ultra minimaliste de la législation, nous heurte. Pourquoi ? Parce que précisément, toujours parce que vous le savez désormais, nous pouvons interpréter la question en ces termes:
"Peut-on réaliser du tracking server-side sans consentement ?"
Et la CNIL répond : "Oui".
Le lecteur comprendra que les conséquences pour l'utilisateur sont, quelle que soit la technologie utilisée, les mêmes : un profilage, une collecte de données personnelles et parfois un partage de celles-ci. Tout ceci donc, non seulement potentiellement sans consentement, mais encore avec la bénédiction de la CNIL. On est en droit de se poser sérieusement la question de savoir pour qui joue notre APD. S'il est compréhensible et même fondamental que notre autorité de contrôle accompagne les entreprises dans leur démarche de politique de confidentialité, qui est loin d'être simple à mettre en place, il faut tout de même rappeler son rôle premier, décrit par l'article 51(1) du RGPD reproduit ci-dessous :.

De la même façon, ce que nous pourrions appeler l "hystéresis juridique permanente", c'est-à-dire l'éternel décalage entre ce qui est réglementairement décrit et encadré, et les nouvelles technologies auxquelles le législateur doit faire face et s'adapter, reste largement exploité par l'Adtech. Il n'empêche : la recherche permanente d'imprécision ou de vide réglementaire aux fins d'exploitation publicitaire doit être prévenue et anticipée par l'autorité de contrôle à notre sens. C'est pourquoi répondre de cette façon à une question aussi pernicieuse nous surprend, ceci d'autant plus que la technologie server side n'est tout de même pas des plus récentes.
On perçoit au travers de cette réponse la stratégie de la CNIL depuis l'entrée en vigueur du RGPD. Elle est potentiellement préoccupante. Nous aurions tendance à l'appeler "La stratégie de la chèvre et du chou". On sent bien, en dehors des infractions manifestes commises par certains organismes, que la CNIL tend à préserver les modèles économiques en place tout en souhaitant protéger l'Internaute : une position difficillement tenable dans la durée à notre sens. S'agit-il d'une spécificité française ? Possiblement, non : il suffit d'observer le comportement de l'autorité de contrôle irlandaise, la DPC, pour se rendre compte que l'impartialité, la rigueur et le zèle dans les investigations ne sont pas toujours de mise. On renvoie le lecteur au feuilleton "DPC-contre-Meta", consécutif à une plainte de l'ONG NOYB datant de 2018, et "synthétisée" sur son site, ici.
Même si cela peut sembler très polémique et sans pour autant évoquer de réels conflits d'intérêts (ce qui serait franchement extrapoler), on s'estime en droit se poser la question au sujet des hauts-fonctionnaires en place au sein de la CNIL. Qui sont-ils ?
Pour certains, des juristes spécialisés dans la protection des données, qui viennent et (re)partent bien souvent au service de l'Adtech. C'est ainsi qu'un ancien secrétaire général de notre APD se retrouve aujourd'hui à défendre l'une des plus grande société au monde de retargeting et de retail media devant.... La CNIL. C'est également ainsi que le chef du département "secteur économique" de la CNIL est aujourd'hui consultant indépendant... Pour quels clients ? A titre de comparaison, nous pouvons donner l'exemple d'une juriste travaillant auparavant pour l'association NOYB, aujourd'hui employée par... le Comité Européen de Protection des Données. Pas le même Touch, il faut le dire.
Il est à notre sens primordial de rester focalisé sur les fondamentaux du RGPD, et de se (re)poser la question : pour quelle raison celui-ci a-t-il été conçu ? Réponse : pour protéger l'usager, et non préserver un modèle économique ou le faire transiter en douceur afin de réduire les pertes pour l'Adtech. Que la CNIL audite et fasse appliquer le RGPD, c'est là notre souhait. Bien d'autres entités existent pour agir en contrepoids : que chacun tienne son rôle. Au delà des considérations techniques et juridiques, l' "esprit du RGPD" évoqué se doit d'être présent dans les consciences de chacun, pour le bien de tous.
Dignilog.